Performance Tuning Tips for Hibernate and Java Persistence
This article is an extract of the chapter Performance of my book Hibernate and Java Persistence by Example.
The book is available in English as eBook (PDF document) and in German as paper book. The eBook is continuously updated and covers the newest features of Hibernate. You will find a complete table of content on my website http://www.laliluna.de
Introduction
There is a incredible choice of options to improve the performance of Hibernate based application. This chapter describes quite a number of them. Each part starts with a small use case describing the problem or requirement. After this you will find a detailed solution how to solve the problem.
Source code for the samples can be found in the project DeveloperGuideAnnotation. Have a look in the package de.laliluna.other.query.
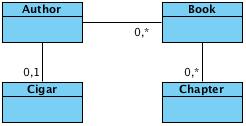
Some of the use cases make use of the following class structure:
Debugging to analyse the performance problem
Scenario
If a dialog is too slow, there might happen a lot of unexpected queries. This can be caused by eager loading of relations or you might just reuse the queries of another dialog. Did you know for example that 1:1 and n:1 relations are loaded eagerly, if you use annotations whereas XML mappings are lazy by default.
Solution
The best approach is to analyse what is happening behind the scenes. Hibernate offers two configuration settings to print the generated SQL. The first one is a property in the hibernate.cfg.xml
<property name="show_sql">true</property>
If it is set to true, the SQL statements will be printed to the console. You will not see any timestamps, this is why I prefer the second approach, which uses the normal logging output.
# logs the SQL statements
log4j.logger.org.hibernate.SQL=debug
# Some more useful loggings
# Logs SQL statements for id generation
log4j.logger.org.hibernate.id=info
# Logs the JDBC-Parameter which are passed to a query (very verboose)
log4j.logger.org.hibernate.type=debug
# Logs cache related activities
log4j.logger.org.hibernate.cache=debug
There are more useful settings in the Hibernate configuration hibernate.cfg.xml
The property format_sql will nicely format the SQL instead of printing it on a single line.
<property name="format_sql">true</property>
The property use_sql_comments adds a comment to each SQL explaining why it was created. It let's you identity if a HQL statement, lazy loading or a criteria query led to the statement.
<property name="use_sql_comments">true</property>
Another good source for information are the statistics of Hibernate.
You can enable the statistics in the Hibernate configuration or programmatically. The statistics class offers a number methods to analyse what has happened. Here a quick example:
Statistics statistics = sessionFactory.getStatistics();
statistics.setStatisticsEnabled(true);
statistics.logSummary();
Furthermore you can call getStatistics on a session as well to gather information about it.
Iterating through relations efficiently - load in batches
Scenario
The application retrieves all books for an author. It iterates through all chapters and counts the number of characters. An alternative scenario could go through orders of a customer and check if one of the order position can already be delivered.
The query for the books:
List<Book> books = session.createQuery(
"from Book b where b.name like ?").setString(0, "Java%").list();
The following code printing the books will create one SQL query per book to initialize the chapters. We get 1+n queries in total. One for the books and n for the chapters, if we have n books.
for (Book book : books) {
int totalLength = 0;
for (Chapter chapter : book.getChapters()) {
totalLength += (chapter.getContent() != null ?
chapter.getContent().length() : 0);
}
log.info("Length of all chapters: " + totalLength);
}
Solution
One way to improve this is to define that Hibernate loads the chapters in batches. Here is the mapping:
Annotations
@OneToMany(cascade = CascadeType.ALL)
@JoinColumn(nullable = false)
@BatchSize(size = 4)
private Set<Chapter> chapters = new HashSet<Chapter>();
XML
<set name="chapters" batch-size="4">
<key column="book_id"></key>
<one-to-many/>
</set>
When iterating through 10 books, Hibernate will load the chapters for the first four, the next four and the last two books together in a single query. This is possible because the java.util.List returned by Hibernate is bewitched. Take the sample code of this chapter and play around with the batchsize in the method efficientBatchSizeForRelation in the class PerformanceTest.
The best size of the batch size is the number of entries you print normally on the screen. If you print a book and print only the first 10 chapters, then this could be your batch size.
It is possible to set a default for all relations in the Hibernate configuration.
<property name="default_batch_fetch_size">4</property>
Use this property with care. If you print on most screens the first 5 entries from a collection, a batch size of 100 is pretty useless. The default should be very low. Keep in mind that a size of 2 reduces the queries already by 50 % and 4 by 75 %.
Iterating through relations efficiently - load all with a query
Scenario
There is still the same problem but we solve it with a different query.
Solution
With join fetch we can tell Hibernate to load associations immediately. Hibernate will use a single SQL select which joins the chapters to the book table.
List<Book> books = session.createQuery(
"select b from Book b left join fetch b.chapters where b.name like ?")
.setString(0, "Java%")
.setResultTransformer(Criteria.DISTINCT_ROOT_ENTITY).list();
The same with a criteria query:
List<Book> books = session.createCriteria(Book.class)
.setFetchMode("chapters", org.hibernate.FetchMode.JOIN)
.add(Restrictions.like("name", "Java", MatchMode.START))
.setResultTransformer(Criteria.DISTINCT_ROOT_ENTITY).list();
The performance is very good but we must be aware that we will load all chapters into memory. Finally, don't use join fetch with multiple collections, you will create a rapidly growing Cartesian product. A join will combine all possible combinations. Let's do a SQL join on data where every book have two chapters and two comments.
select * from book b left join chapters c on b.id=c.book_id left join comment cm on b.id=cm.book_id
|
Book id |
Other book columns |
Chapter id |
Other chapter columns |
Comment id |
Other comment columns |
|
1 |
... |
1 |
... |
1 |
... |
|
1 |
... |
1 |
... |
2 |
... |
|
1 |
... |
2 |
... |
1 |
... |
|
1 |
... |
2 |
... |
2 |
... |
Reporting queries
Scenario
For a report you need to print the name of the author, the number of books he wrote and the total of chapters in his books. If your dataset consists of 10 authors with 10 books each and each book having 10 chapters, you will end up with 1000 objects in memory. The report requires only 10 java.lang.String and 20 java.lang.Integer.
Solution
The problem can easily be solved with a reporting query. The following query returns a list of Object arrays instead of entitys.
List<Object[]> authorReportObjects = session.createQuery("select a.name, " +
"count(b) as totalBooks, count(c) as totalChapters " +
"from Author a join a.books b join b.chapters c group by a.name").list();
for (Object[] objects : authorReportObjects) {
log.info(String.format("Report: Author %s, total books %d, total chapters %d", objects[0], objects[1], objects[2]));
}
An alternative is to fill a Java class dynamically. If you use HQL you might call the constructor with a corresponding arguments or with both HQL and criteria you can use an AliasToBeanResultTransformer. In that case the Java class needs to have the same properties as the column names of your query.
Constructor approach:
List<AuthorReport> authorReports = session
.createQuery("select new de.laliluna.other.query.AuthorReport(a.id, a.name, " +
"count(b), count(c)) " +
"from Author a join a.books b join b.chapters c group by a.id, a.name").list();
for (AuthorReport authorReport : authorReports) {
log.info(authorReport);
}
AliasToBeanResultTransformer approach:
List<AuthorReport> authorReports = session
.createQuery("select a.name as name, count(b) as totalBooks, count(c) as totalChapters " +
"from Author a join a.books b join b.chapters c group by a.name")
.setResultTransformer(new AliasToBeanResultTransformer(AuthorReport.class)).list();
for (AuthorReport authorReport : authorReports) {
log.info(authorReport);
}
Summary
I hope you found some useful tips in the article. I wish you all the best for your Hibernate projects.