Table of Contents
Relation mapping is the mapping of classes which have a relation. For example Team has a relation to a department and to a Set of Member.
Department 1:n Teams m:n Members.
public class Team {
private Integer id;
private String name;
private Department department;
private Set members = new HashSet();
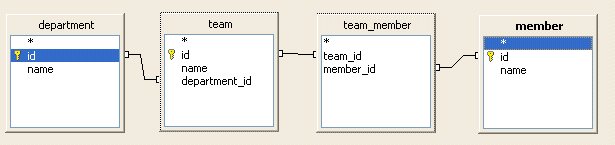
Team can be initialized by Hibernate so that team.getDepartment will give you the Department and team.getMembers will get you a Set of Members.
If you map a 1:n or a m:n relation you will have a class holding references to many of the other class. Here is the class diagram of our first example:
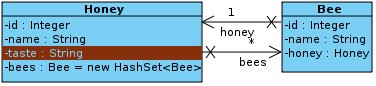
The field bees in Honey was of type java.util.Set. Hibernate supports other types as well. In general you can distinguish the following types:
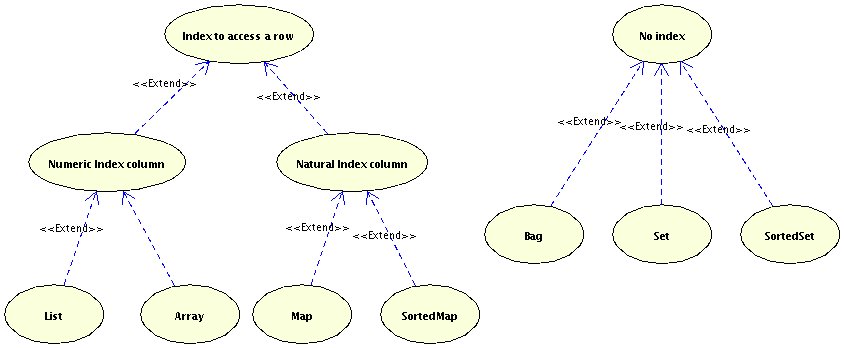
The main difference between these approaches is the presence or lack of an index column. A mapping with an index column is very fast to update. The numeric index is a column starting with a 0 for the first element, a 1 for the second and so on. If you delete an entry, all following index columns must be updated. This is of course slower. The following lines gives further tips for selection an option. Although it is more oriented to XML mapping, have a look at it.
Selecting XML mappings
Each option fit different requirements. The provided source code Developer Guide package de.laliluna.relation.overview holds a simple example of all types of mappings 1:n The following table gives an overview of XML mapping options.
| Annotation mapping | XML mapping | Corresponding java type | Pros and cons |
|---|---|---|---|
set | java.util.Set | Fast, does not need an index | |
map | java.util.Map | Fast to update.Needs an index column equivalent to map key, to access the entry. | |
map | java.util.SortedMap | Same as map, In addition, sorting by a comporator is supported | |
list | java.util.List | Fast to update. Needs an index column | |
bag | java.util.List | Quite slow to update, because the whole bag has to be searched. A bag can have double entries | |
array | Array of any mapped object | Needs an index column | |
primitive-array | Array of Integer, String, | Needs an index column |
What do I use?
I use a Set in most cases. If I need a sort order, I make use of SortedSet. If I need some kind of natural order or I have to update single entries of a relation very often, I use List. The use of Map is rare. It is useful, if your data has some kind of natural map. In the sample below, we have languages, where the iso country code was used as key. The rest may have some rare use cases, but in my opinion, you will need them in very rare situation.
Selecting annotation mapping
Annotations do not provide the same structure. You are not forced to use java.util.List with the list mapping or a java.util.Set with a set. There is only have a annotation and you are allowed to use a List, a Set or a Collection. Of course, in case you want to use a map you need a type of java.util.Map. Source code for the following samples can be found in package de.laliluna.relation.overview.
Non indexed
Set hobbies = new HashSet();
Simplified and not perfectly correct: a set works like a map having a hash as a key and the object as value. A hash is a artificial number generated from the data. The number should be unique. Java accesses an entry in a HashSet by the generated hash. The java.lang.Object class implements a hashCode method.
Table 7.1. Sample hash
| Hash | Value |
|---|---|
7043360 | a object of type Developer |
8812347 | an other developer |
1234536 | and a third one |
Updates to an entry might be slower than an update to an indexed row, but if you delete a row there are no side effects (e.g. index update) to other elements.
Annotation mapping.
@OneToMany(cascade = CascadeType.ALL) @JoinColumn(name = "developer_id") private Set<Hobby> hobbies = new HashSet<Hobby>();
The @JoinColumn is actually not necessary. By default the foreign key column would be named developer_id anyway. If you use annotations, you can use a List as well.
@OneToMany(cascade = CascadeType.ALL) @JoinColumn(name = "developer_id") private List<Hobby> moreHobbies = new ArrayList<Hobby>();
XML mapping.
<set name="hobbies" cascade="all"> <key column="developer_id" not-null="true"></key> <one-to-many class="Hobby" /> </set>
This mapping does not need an index column as map or list. The definition will create a table like
CREATE TABLE thobby ( id int4 NOT NULL, name varchar(255), developer_id int4, PRIMARY KEY (id), ... snipped away the foreign key constraints ... )
Non indexed but sorted
private SortedSet<Sport> sports = new TreeSet<Sport>(new SportComparator());
The characteristics of a sorted set are identical to a Set. In addition, a sortedSet can be sorted. This is not made by the database but in memory. Have a look at the TreeSet documentation of Java to find out more. One option to sort is to pass a comparator to the TreeSet. The comparator below sorts Sport items by name.
import java.util.Comparator;
public class SportComparator implements Comparator<Sport> {
public int compare(Sport o1, Sport o2) {
if (o1 = null || o1.getName()= null)
return 1;
if (o2 = null || o2.getName()= null)
return -1;
return o1.getName().compareTo(o2.getName());
}
}Another option is to implement the Comparable interface in the Sport class. This kind of sorting is called natural sort. In this case you have to apply the SortType.NATURAL.
Annotation mapping.
@OneToMany(cascade = CascadeType.ALL) @JoinColumn(name = "developer_id") @Sort(type = SortType.COMPARATOR, comparator = SportComparator.class) private SortedSet<Sport> sports = new TreeSet<Sport>(new SportComparator());
XML mapping.
<set name="sports" cascade="all" sort="de.laliluna.example1.SportComparator"> <key column="developer_id" not-null="true"></key> <one-to-many class="Sport" /> </set>
It is probably faster to sort large sets by the database.
Table structure.
CREATE TABLE tsport ( id int4 NOT NULL, name varchar(255), developer_id int4 NOT NULL, PRIMARY KEY (id), ... snipped away the foreign key constraints ... )
Non indexed with a bag mapping
private List ideas = new ArrayList();
A bag has no index. So access to an element always needs to traverse the complete bag until the element is found. This is only an issue when your bag can be large. Another disadvantage is that one element can be in a bag more than once. So you must be careful when adding entries to a bag. This kind of mapping is only supported by XML mappings
XML mapping.
<bag name="ideas" cascade="all">
<key column="developer_id" not-null="true"></key>
<one-to-many class="Idea" />
</bag>
Table structure.
CREATE TABLE tidea ( id int4 NOT NULL, name varchar(255), developer_id int4, PRIMARY KEY (id), ... snipped away the foreign key constraints ... )
There is one situation when a bag can be faster than a set. Having a bi-directional one-to-many relation where inverse="true", i.e. the relation is managed on the one-side as opposed to our example.
Developer d = session.get(Developer.class, 4711); Idea idea = new Idea(); idea.setDeveloper(d); d.getIdeas().add(idea);
In this case the getIdeas method does not need to initialize the ideas list. When there are many ideas this can be a great speed advantage. Indexed using a java.util.Map
private Map developmentLanguages = new HashMap();
A map is a data structure where each value is accessed by a key. The value can be any kind of object, starting from primitives (String, Integer, …) to normal objects. When your data is similar to the following table you might consider using a map.
| Short name | Country |
|---|---|
de | Germany |
us | United States |
fr | France |
A map is quite fast, as the key is used as an index to the data.
Annotation mapping.
@CollectionOfElements
@JoinTable(name = "development_languages", joinColumns =
@JoinColumn(name = "developer_id"))
@Column(name = "name", nullable = false)
private Map<String, String> developmentLanguages = new HashMap<String, String>();
If we want to change the column of the key, we can overwrite the default column name mapkey in front of the class with the following annotation:
@AttributeOverrides( {
@AttributeOverride(name = "developmentLanguages.key",
column = @Column(name = "short_name"))
})
public class Developer implements Serializable {XML mapping.
<map name="developmentLanguages" table="tdevelopmentlanguage" cascade="all"> <key column="developer_id" not-null="true"></key> <map-key type="string" column="shortname"></map-key> <element column="name" type="string"></element> </map>
Table structure.
CREATE TABLE tdevelopmentlanguage ( developer_id int4 NOT NULL, name varchar(255), shortname varchar(255) NOT NULL, PRIMARY KEY (developer_id, shortname), ... snipped away the foreign key constraints ... )
Below you can see a map mapping to an object
@OneToMany(cascade=CascadeType.ALL)
@JoinColumn(name="developer_id")
@MapKey(name="isocode")
private Map<String, LovedCountry> lovedCountries =
new HashMap<String, LovedCountry>();CREATE TABLE lovedcountry ( isocode varchar(255) NOT NULL, name varchar(255), developer_id int4, PRIMARY KEY (isocode), ... snipped away the foreign key constraints ... );
Indexed and sorted using java.util.SortedMap
private SortedMap lovedCountries = new TreeMap();
A sorted map shares the features of the java.util.Map and can be sorted like the SortedSet. The sort is not made by the database but in memory. Have a look at the TreeMap documentation of Java to find out more. It is probably faster to sort large maps by the database. This is currently not supported with annotations but you might mix in a XML mapping. indexterm:[<composite-element>}
XML mapping.
<map name="lovedCountries" cascade="all" sort="natural">
<key column="developer_id" not-null="true"></key>
<map-key type="string">
<column name="isocode"></column>
</map-key>
<composite-element class="LovedCountry">
<property name="name" type="string"></property>
</composite-element>
</map>
Table structure.
CREATE TABLE tlovedcountries ( developer_id int4 NOT NULL, name varchar(255), isocode varchar(255) NOT NULL, PRIMARY KEY (developer_id, isocode), ... snipped away the foreign key constraints ... )
Indexed with numeric index using java.util.List
private List computers = new ArrayList();
A list mapping always has an index column, if you use XML mapping. This allows a fast access to an element by the index. To remove an entry in a list is slower as compared to a Set. The reason is that all the following entries need to get an updated index value. Another advantage of an indexed List is that the entries will keep their sort order.
Annotation mapping.
@OneToMany(cascade = CascadeType.ALL) @JoinColumn(name = "developer_id") @IndexColumn(name = "listindex") private List<Computer> computers = new ArrayList<Computer>();
XML mapping.
<list name="computers" cascade="all">
<key column="developer_id" not-null="true"></key>
<list-index column="listindex"></list-index>
<one-to-many class="Computer" />
</list>
Table structure.
CREATE TABLE tcomputer ( id int4 NOT NULL, name varchar(255), developer_id int4 NOT NULL, listindex int4, PRIMARY KEY (id), ... snipped away the foreign key constraints ... )
Indexed with an idbag mapping
private List dreams = new ArrayList();
An idbag mapping is only suitable for many-to-many mappings. It has an index, it is defined by the tag collection-id. So an update is as fast as a set, list or map. Note: the primary key generator of type native is not supported at the moment. Once again this kind of mapping is not supported by annotations. Closest is probably a List mapping with an index column.
XML mapping.
<idbag name="dreams" cascade="all" table="developer_dream"> <collection-id type="integer" column="id"> <generator class="sequence"> <param name="sequence">developer_dream_id_seq</param> </generator> </collection-id> <key column="developer_id" not-null="true"></key> <many-to-many column="dream_id" class="Dream"></many-to-many> </idbag>
Table structure.
CREATE TABLE developer_dream ( developer_id int4 NOT NULL, dream_id int4 NOT NULL, id int4 NOT NULL, PRIMARY KEY (id), ... snipped away the foreign key constraints ... )
Indexed - array of objects
private JuneBeetle juneBeetles[];
In my opinion, an array is only useful if you do not have to add or remove items from your array. An array always needs an index column.
Annotation mapping.
@OneToMany(cascade = CascadeType.ALL) @JoinColumn(name = "developer_id") @IndexColumn(name = "listindex") private JuneBeetle juneBeetles[];
XML mapping.
<array name="juneBeetles" cascade="all"> <key column="developer_id" not-null="true"></key> <list-index column="listindex"></list-index> <one-to-many class="JuneBeetle" /> </array>
Table structure.
CREATE TABLE tjunebeetle ( id int4 NOT NULL, name varchar(255), developer_id int4, listindex int4, CONSTRAINT tjunebeetle_pkey PRIMARY KEY (id), ... snipped away the foreign key constraints ... )
Indexed - array of primitives
private Integer[] favouriteNumbers;
You will probably need this mapping only in rare cases, i.e. if you need access to primitives. An array always needs an index column. This kind of mapping is not EJB3 compliant and only possible with Hibernate extensions (CollectionOfElements ).
Annotation mapping.
@CollectionOfElements @IndexColumn(name = "listindex") private int[] favouriteNumbers;
XML mapping.
<primitive-array name="favouriteNumbers" table="tfavouritenumber"> <key column="developer_id"></key> <list-index column="listindex" base="0"></list-index> <element type="integer" column="number"></element> </primitive-array>
Table structure.
CREATE TABLE tfavouritenumber ( developer_id int4 NOT NULL, number int4, listindex int4 NOT NULL, CONSTRAINT tfavouritenumber_pkey PRIMARY KEY (developer_id, listindex), ... snipped away the foreign key constraints ... )